Understanding How IoT Systems Scale And Evolve
The next wave of the Internet won’t be about people. The Internet of Things (IoT) will connect machines and devices together into functioning, intelligent systems. It promises to transform many industries. Much of the buzz is about consumer devices: how your thermostat can adapt to your lifestyle, or how your sprinklers will save water by knowing when it’s going to rain.
Related Articles
- Understanding The Protocols Behind The Internet Of Things
- The Internet Of Things Can Save 50,000 Lives A Year
- Looking Forwards And Backwards On The Internet Of Things
But the more exciting applications are the new, complex, distributed systems that simply aren’t possible today: intelligent cars and highways, smart energy grids, and brilliant hospitals built of connected devices. These complex systems must be assembled from distributed components that connect through an information distribution and sharing technology.
This file type includes high resolution graphics and schematics when applicable.
Data-Centric Infrastructure
Several protocol standards address IoT challenges.1 The Data Distribution Service (DDS) most directly addresses the development of intelligent distributed machines. DDS can deliver data at physics speeds to thousands of recipients with strict control of timing, reliability, failover, and language and operating system (OS) translation.
Air traffic control systems such as Nav Canada, large wind farms from Siemens, and complex medical devices all are complex DDS IoT applications. These systems clearly need performance, reliability, and scale. But some of the larger challenges are not so obvious. One of the most critical yet rarely understood problems is system complexity management and evolution.
Large distributed systems may include thousands of applications with millions of connections. Through DDS, these applications share information by publishing or subscribing to the data they need. DDS discovers the sources and sinks of information, matches the requirements on both sides, and then delivers the data as ordered.
DDS is a data-centric technology. It locates, filters, controls, and exchanges information flow with a known data model. Data centricity is not a new concept. Databases are data-centric technologies for storage. DDS is a data-centric technology for moving data. Like a database, DDS manages the system data types and interfaces for distributed systems.2
Why Data Centricity Improves Scaling
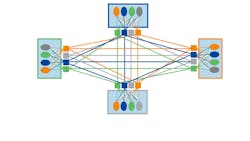
Earlier generations of middleware left management of all the data types and interfaces to the applications. Figure 1 represents these “distributed object” designs. The circles of different colors represent different types and state of data. The squares are interfaces to that data. Each application must understand each other application’s interfaces and state. Although the interface may hide the internal structure of the state, the external transmitted type must be understood, somehow, by the receiving application. Thus, it cannot really be hidden.

This is how object-oriented (OO) programming works. The “data access method” technique is simple and intuitive for small systems. However, distributed systems are not like OO programs. For any meaningful use of data, it’s not practical to call access methods over a network. So, each application both needs to know the interface (methods) to call and to store some internal data representation (state) of the remote application.
In a “fully meshed” system of size n, adding a new participant forces every existing participant to add an interface (n total) and a remote state (n total), and it itself needs n of each. By some rough measure, then, the complexity of this object design scales as 4n2, where n is the number of applications. As a result, this design is impractical for large systems (Fig. 2).
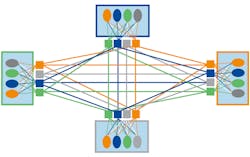
“Message oriented” middleware came along and standardized the interfaces. With messaging, all information is now exchanged as messages through a common interface. Message-oriented middleware passes opaque messages of unknown type. Consequently, each application must still manage its peer’s remote state. Still, this is a great improvement. It scales as n2(Fig. 3).
Messaging designs allowed distributed systems to scale to much larger sizes. Enterprise systems using messaging middleware combined tens or, in the case of Web services, even hundreds of interacting applications. Most of these systems are “large grained,” built from very large applications with complex exposed interfaces.
However, the IoT must encompass even larger scales. IoT systems will be built from thousands of different “finer grained” applications. For instance, hospitals comprise tens of thousands of different devices. Smart grids include thousands of nodes. In fact, some leading systems are already this complex. The new DDG-1000 destroyer, for instance, has over 1500 applications and millions of publish-subscribe pairs. Message-oriented middleware can’t handle that scale.
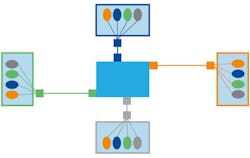
Data-centric middleware adds an important new functionality: the data model. Data-centric infrastructure understands data schema. In the storage world, this is implemented as database “tables” with known structured data. In the analogous data-centric distributed networking, DDS systems exchange data of known types. The state representation is now delegated to the infrastructure, simplifying all applications. This scales as O(n) (Fig. 4). The state itself is synchronized by the type-aware middleware.
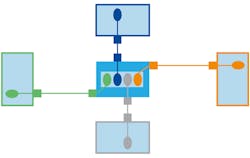
Practically, this means that applications no longer directly access each other’s state. Instead, they interact only with the infrastructure. In the database storage case, applications interact with the data tables through a well-defined CRUD (create, read, update, delete) interface. The database infrastructure enforces rules like data consistency and access control. In the distributed data case, applications interact with a “virtual global data space,” also with a CRUD-like interface. The middleware infrastructure enforces contracts between participants like access control, timing, reliability, and system health guarantees.
Perhaps more importantly, because it understands the data, a data-centric infrastructure can be selective about what data it provides. DDS, for instance, offers “content filtering.” An application can request only information about objects in a specified region or only physiological parameters that are out of normal range. Even time is modeled. An application can request an update no more than 10 times a second. The middleware will not even send the uninteresting data, reducing bandwidth while it simplifies the application. Messaging technologies cannot do that.
Data-Type Evolution
Because it reduces application complexity, data-centricity enables larger systems. However, there is another consideration for large systems: data model evolution over time. To use the delivered data, the applications must agree on the data schema or types. And therein lies the challenge. In a large system, these types cannot be static.
To understand this, imagine building a large, distributed system. You can’t write 1500 applications in a matter of months or with a single tight-knit team. Even if the initial teams are extraordinarily well coordinated, the types defined during the development of, say, the first 400 applications may need to evolve during the creation of the next 375, because those applications need to share more data.
Of course, the 500 after that may again change those types. When portions of the original system are upgraded, the type confusion only grows. Worse, if deployed systems must interoperate, all versions have to somehow work together. Fundamentally, type evolution is a critical requirement for any large software system that must last and evolve for years.
Databases of course also suffer from this system evolution effect. They solve it with refactoring algorithms that can tune table schema to each application’s needs. The DDS DataBus standard faces a similar problem, made more difficult because each application is physically remote. DDS solves that problem with a technology called extensibility. The full name of the standard is Extensible and Dynamic Topic Types for DDS, commonly known as the DDS XTypes specification.
There are many ways that types can evolve. The simplest is called extensible extensibility. That mouthful simply means that types can evolve by extending the type, i.e. by adding new elements at the end. (Why can’t this be called field addition extensibility? Perhaps that’s too colloquial for a standard.)
Consider a GPS vehicle-tracking system. In a first implementation, the VehicleData type may provide position information such as latitude and longitude (Fig. 5). In a second implementation, the vendor may decide to add speed as part of the VehicleData information.
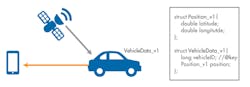
Without a way to evolve the types, the devices that subscribe to vehicle data without speed will not be able to interoperate with vehicles publishing vehicle data with speed. Likewise, new devices that read vehicle data with speed will not interoperate with vehicles that do not publish speed data. DDS extensible extensibility allows both versions of the type to coexist in the same system. Notice in Figure 6 that the VehicleData type evolved by adding the speed at the end.
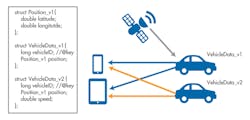
Under the hood, the DDS middleware is keeping track of the version of the type understood by each vehicle and device. When it receives a request from an application to subscribe to a vehicle, the middleware checks to see if the application and vehicle types are the same. If not, it will add or strip the extra field as required on subsequent updates. It’s conceptually simple. The need to grant applications some control over how to handle critical changes complicates things a bit, though that level of issue is beyond this treatment.
Simple extension handles many use cases. However, consider what happens if a third version of the system must track not only ground vehicles but also air vehicles. To do that, the position type has to evolve again to include altitude (see the code).

Extensible extensibility does not support this kind of evolution because VehicleData_v3 has not been evolved from VehicleData_v2 by adding new members at the end but by changing the structure of the common member position.
DDS XTypes support this kind of evolution with mutable extensibility. A mutable type can evolve by adding, removing, or changing the order of the members as long as the common members are compatible with each other. By adding support for mutable extensibility, we can have a system in which new and old components can exchange VehicleData (Fig. 7).
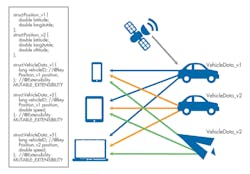
There are, of course, subtleties. For example, the data exchange may lead to semantic errors. Consider a reading device, an iPad, that visualizes VehicleData_v3 data (with altitude). If the device receives data from a vehicle publishing VehicleData_v2 (without altitude), the altitude value will be set to a default value of zero.
The iPad may need to differentiate between types of vehicles by the data itself. What should the iPad do with that? Zero is a valid altitude value. Are we looking at an airplane on the ground? Or is this a car that does not provide altitude?
To resolve these kinds of ambiguities, DDS introduces support for optional members, which are modeled after nullable columns in SQL. When a member is marked as optional it can be assigned a NULL value, which means that either the value is not known or it does not exist. Thus, DDS supports type extensions (adding fields), mutations (changing field order, addition or deletion) and optional members (partial structure matching). This greatly simplifies the challenges faced by applications.
Complexity Management
Data-centric middleware enables scaling by managing both interfaces and types. With DDS XTypes, it also allows for type evolution by supporting extensible types, communicating to each application in the “version” of the type that the application expects. So, DDS provides the flexible glue that ties everything together.
You may think that this just shifts the complexity into the infrastructure and overly complicates the middleware. That is a valid worry. Data-centric technology already takes more investment to understand and use than simpler messaging systems. This seems to add another level of complexity.
However, putting this complexity into the infrastructure has a key advantage over putting it into applications. The middleware approach controls and clarifies exactly how interactions occur in one place. Without data centricity, every application must interpret every other application’s state. Without extensibility, every application also requires code changes to adapt to the changes in all other applications. Such a system, at large scale, would be immensely complex and unmaintainable. In fact, interface explosion and version evolution are key reasons for software obsolescence.
DDS moves that complexity into one place, the middleware. This greatly simplifies the applications. In a data-centric system, the infrastructure understands and manages the state. With extensibility, the middleware also absorbs all the version changes.3 The complexity is then contained in one part of the system. And, better contained complexity is better managed complexity. Just as database technology allowed much more complex enterprise systems, data-centric middleware enables much more complex distributed systems. Both technologies do that by centrally managing complexity.
System complexity and evolution are unavoidable. The world cannot stop to adapt to it. Data-centric, extensible technology is essential to the rise of the complex distributed systems that drive the Internet of Things.
References
1. “Understanding The Protocols Behind The Internet Of Things,” Stan Schneider, http://electronicdesign.com/embedded/understanding-protocols-behind-internet-things
2. “What’s The Difference Between Message Centric And Data Centric Middleware?” Stan Schenider, http://electronicdesign.com/embedded/whats-difference-between-message-centric-and-data-centric-middleware
3. Of course, this is not 100% doable. For instance, DDS allows declarations like the subscriber “must understand” an extension. But this relatively minor increased infrastructure complexity greatly simplifies applications.
Stan Schneider is the founder of RTI. He completed his PhD in electrical engineering and computer science at Stanford University. He holds a BS in applied mathematics (Summa Cum Laude) and an MS in computer engineering from the University of Michigan. He is a graduate of Stanford’s Advanced Management College as well.

About the Author
Stan Schneider
CEO, Real-Time Innovations
Dr. Stan Schneider is CEO of Real-Time Innovations (RTI), the Industrial Internet of Things connectivity company. Stan serves as Vice Chair of the Industrial Internet Consortium (IIC) Steering Committee. He also serves on the advisory board for IoT Solutions World Congress, and chairs OpenFog's Fog World keynote committee. He was named Embedded Computing Design’s Top Embedded Innovator Award 2015 & IoTOne’s top-10 most influential in the IIoT 2017.He holds a PhD in EE/CS from Stanford.
Fernando Sanchez
Principal Engineer
Fernando Crespo Sanchez is a principal engineer at RTI. He has been with RTI since 2004. His technical expertise spans large-scale real-time distributed systems and embedded systems. At RTI, he is an architect for the RTI Connext DDS product. He holds a MS in computer science from the University of Granada. He can be reached at: [email protected].
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: