A Deeper Look at Deep-Learning Frameworks
This file type includes high-resolution graphics and schematics when applicable.
Deep learning is one aspect of artificial intelligence (AI) that continues to advance, owing to performance improvements in multicore hardware such as general-purpose computation on graphics processing units (GPGPUs). Tools and frameworks have also made deep learning more accessible to developers, but as of yet, no dominant platform like C has emerged. The plethora of choices can be confusing, and not all platforms are created equal. It’s also an area where cutting-edge development perpetually makes it more difficult to create new applications on top of a solid base.
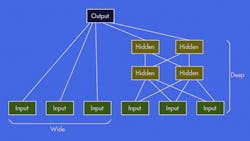
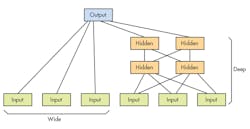
Deep learning is another name for deep neural networks (DNNs). This type of neural network has many layers, which affects computation requirements: As the size of a layer and number of layers increases, so do those requirements. In addition, wide neural networks, which are shallow in nature, can be useful for many applications. In fact, it’s possible to mix them (see figure) using some frameworks. Neural networks are also in play with recurrent neural networks, convolutional neural networks, and logistic regression.
Some of the more popular, open-source, deep-learning frameworks include Caffe, CNTK, TensorFlow, Torch, and DeepLearning4J. Caffe, developed at the Berkley Vision and Learning Center (BVLC), probably has the greatest following and support. Microsoft’s Computational Network Toolkit (CNTK) is an active open-source project. Torch and Theano are Python libraries that provide deep-learning support. MatConvNet is a toolbox designed for Mathworks’ MATLAB.
Google started TensorFlow. The TensorFlow Playground is a website where you can experiment with predefined networks to see how changes affect the recognition process and its accuracy. DeepLearning4J, developed by Skymind, is a deep-learning framework written in Java that’s designed to run on a Java Virtual Machine (JVM). The Skymind Intelligence Layer (SKIL) is based on Deeplearning4J, ND4J, and LibND4J (an n-dimensional array library).
DNN Underpinnings
Most of the DNN platforms often utilize new or existing computational frameworks to do the heavy lifting required by applications. Two well-known computational frameworks are OpenCL and Nvidia’s cuDNN (CUDA DNN). OpenCL has the advantage of running on a range of hardware from multicore CPUs to GPGPU arrays. Nvidia’s solution targets its own GPUs, including the latest Pascal architecture, Tesla P100 (see “GPU Targets Deep Learning Applications”).
DNN applications often require significant amounts of training on large computational clusters to determine the weights associated with the nodes or neurons within a neural net. The plus side is that the resulting network can be implemented on much simpler hardware that may include microcontrollers.
The biggest challenge for developers is to become familiar with DNN. The frameworks typically have a number of preconfigured networks for sample applications, such as image recognition. The tools can be used for much more, but it often takes an expert to develop and tune new configurations.
Unfortunately, commercial support is only available for some frameworks. Select companies like Nvidia have an active support program with tools like the Deep Learning GPU Training System (DIGITS), which is designed to handle image classification and object detection tasks. It can help with a range of functions, such as training multiple networks in parallel.
DNNs and their associated tools are not applicable to all applications. However, they can make a significant difference in terms of capability and performance for many application areas, from cars to face recognition on smartphones.
Looking for parts? Go to SourceESB.
This file type includes high-resolution graphics and schematics when applicable.
About the Author

William G. Wong
Senior Content Director - Electronic Design and Microwaves & RF
I am Editor of Electronic Design focusing on embedded, software, and systems. As Senior Content Director, I also manage Microwaves & RF and I work with a great team of editors to provide engineers, programmers, developers and technical managers with interesting and useful articles and videos on a regular basis. Check out our free newsletters to see the latest content.
You can send press releases for new products for possible coverage on the website. I am also interested in receiving contributed articles for publishing on our website. Use our template and send to me along with a signed release form.
Check out my blog, AltEmbedded on Electronic Design, as well as his latest articles on this site that are listed below.
You can visit my social media via these links:
- AltEmbedded on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
- Bill Wong on LinkedIn
I earned a Bachelor of Electrical Engineering at the Georgia Institute of Technology and a Masters in Computer Science from Rutgers University. I still do a bit of programming using everything from C and C++ to Rust and Ada/SPARK. I do a bit of PHP programming for Drupal websites. I have posted a few Drupal modules.
I still get a hand on software and electronic hardware. Some of this can be found on our Kit Close-Up video series. You can also see me on many of our TechXchange Talk videos. I am interested in a range of projects from robotics to artificial intelligence.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: