What’s the Difference Between SPARK 2014 and Apache Spark?
>> Website Resources
.. >> Library: TechXchange
.. .. >> TechXchange: Embedded Software
.. .. .. >> Topic: Ada and SPARK
What’s the difference between SPARK 2014 and Apache Spark? Actually, the answer is quite easy. SPARK 2014 is a programming environment based on the Ada programming language. Apache’s open-source SPARK project is an advanced, Directed Acyclic Graph (DAG) execution engine.
Both are used for applications, albeit of much different types. SPARK 2014 is used for embedded applications, while Apache SPARK is designed for very large clusters. Here is a quick overview of each just in case you need more details.
SPARK 2014
SPARK 2014 is the latest incarnation of the SPARK programming environment. The language is a subset of the Ada 2012 programming language that includes features like contract programming.
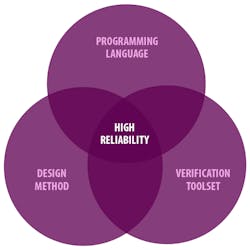
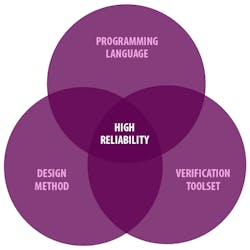
SPARK 2014 consists of a programming language that is a subset of Ada, a design methodology and a verification toolset (see figure). The language subset is chosen so that applications written in SPARK 2014 and be proven to match the specification that is part of the program. It is designed for low defect software that is necessary for programming in general, as well as safety- and security-related applications such as avionics. The matching toolset utilizes the information within application code to statically analyze the program and verify that it matches the specification.
SPARK 2014 is ideal for embedded applications—even those targeting embedded microcontrollers. The subset of Ada retains many of the useful features of Ada, like its packaging system, while remaining compact enough to be more easily understood.
Apache Spark
Apache Spark is a Java virtual machine (JVM)-based cluster framework that runs on top of platforms like Hadoop or Mesos. It can also run on its own and in the cloud. Spark provides programmers with a resilient distributed dataset (RDD). The RDD is a read-only multiset of data items that is distributed throughout the cluster.
Spark Core provides the basic distributed task dispatching system. It supports JVM-based languages like Scala, Java, and R. The Core supports Spark SQL. It is a domain-specific language for manipulating DataFrames, a data abstraction for structured and semi-structured data. Of course, it provides SQL semantics. The Spark Streaming system moves data from Spark data sources and processes the information. Internally it does this in small batches. The other two major pieces to Spark are the MLlib machine learning library and GraphX. The latter is a graph processing framework.
SPARK is a common term adopted by a number of applications, platforms, etc. SPARK 2014 and Apache SPARK are just two; most are as different as these two systems. For example, the Particle Spark Core is a Wi-Fi development kit based on Texas Instruments’ CC3000 chip.
>> Website Resources
.. >> Library: TechXchange
.. .. >> TechXchange: Embedded Software
.. .. .. >> Topic: Ada and SPARK

About the Author

William G. Wong
Senior Content Director - Electronic Design and Microwaves & RF
I am Editor of Electronic Design focusing on embedded, software, and systems. As Senior Content Director, I also manage Microwaves & RF and I work with a great team of editors to provide engineers, programmers, developers and technical managers with interesting and useful articles and videos on a regular basis. Check out our free newsletters to see the latest content.
You can send press releases for new products for possible coverage on the website. I am also interested in receiving contributed articles for publishing on our website. Use our template and send to me along with a signed release form.
Check out my blog, AltEmbedded on Electronic Design, as well as his latest articles on this site that are listed below.
You can visit my social media via these links:
- AltEmbedded on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
- Bill Wong on LinkedIn
I earned a Bachelor of Electrical Engineering at the Georgia Institute of Technology and a Masters in Computer Science from Rutgers University. I still do a bit of programming using everything from C and C++ to Rust and Ada/SPARK. I do a bit of PHP programming for Drupal websites. I have posted a few Drupal modules.
I still get a hand on software and electronic hardware. Some of this can be found on our Kit Close-Up video series. You can also see me on many of our TechXchange Talk videos. I am interested in a range of projects from robotics to artificial intelligence.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: