Framework Ports Deep Neural Network to Vector DSP

Deep Neural Networks (DNNs) are becoming more popular as mechanisms to identify all sorts of object recognition and vision analytic tasks. One open-source platform that is popular in this space is Caffe, a deep-learning framework developed at the Berkeley Vision and Learning Center (BVLC).
Caffe can run on many platforms including GPUs, but this can require powerful and power-hungry platforms. It also utilizes a floating point. Converting algorithms to fixed point can allow these applications to run more quickly while maintaining accuracy within 1% of the original floating point implementation. This is the premise behind CEVA’s new CEVA Deep Neural Network (CDNN).
Deep neural networks use a large number of layers. This approach helps when recognizing features. The network design can be reused and easily trained using new input data.
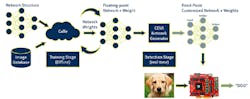
The CDNN framework (Fig. 1) turns floating-point DNNs into more efficient fixed-point that can run on CEVA-XM4 vector DSP architecture. The algorithm and network are normally created using Caffe. A database of images is processed to create the floating point DNN implementation. This in turn is converted by the CEVA software into a fixed-point version that can run on the CEVA-XM4 platform.
Preprocessing images to train the neural network is a typical approach since most embedded applications will not do training in the field. For example, pedestrian and obstacle recognition for an automotive application will need to handle these chores immediately. Its operation also needs to be consistent from one car to another.
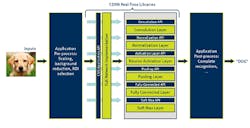
The CEVA framework targets the CEVA real-time libraries (Fig. 2). The library APIs allow an application to run on CEVA hardware or the code can be split so some work can be done by the host.
CEVA worked with Phi Algorithm Solutions to develop the preprocessing operations such as scaling input. This can run on the CEVA hardware or on the host. It can also be replaced by a developer or different third-party implementations can be used.
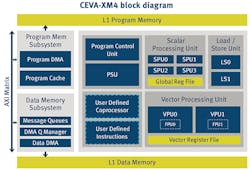
The CEVA-XM4 architecture (Fig. 3) is a vector-processing DSP with a dedicated, pixel processing VLIW/SIMD architecture that contains nine functional units and a 14-stage pipeline. Normally developers will incorporate the CEVA-XM4 IP into a custom system-on-chip (SoC). The architecture supports fixed- and floating-point data. The architecture supports single or multicore implementations. The software can adjust to fully utilize the available hardware.

The resulting system can used 30 times less power a comparable GPU implementation that would use floating-point while being three times faster. It also requires 15 times less memory bandwidth.
The CEVA-XM4 development board (Fig. 4) uses only 28 mW of power to handle a typical pedestrian DNN implementation. The board uses CEVA’s chip. This software can then be ported to the custom SoC. The platform was used to handle the pedestrian recognition application implemented using Phi’s Universal Object Detection (UOD) DNN algorithm. The system can run with a 1080p, 30 frame/s data stream.
About the Author

William G. Wong
Senior Content Director - Electronic Design and Microwaves & RF
I am Editor of Electronic Design focusing on embedded, software, and systems. As Senior Content Director, I also manage Microwaves & RF and I work with a great team of editors to provide engineers, programmers, developers and technical managers with interesting and useful articles and videos on a regular basis. Check out our free newsletters to see the latest content.
You can send press releases for new products for possible coverage on the website. I am also interested in receiving contributed articles for publishing on our website. Use our template and send to me along with a signed release form.
Check out my blog, AltEmbedded on Electronic Design, as well as his latest articles on this site that are listed below.
You can visit my social media via these links:
- AltEmbedded on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
- Bill Wong on LinkedIn
I earned a Bachelor of Electrical Engineering at the Georgia Institute of Technology and a Masters in Computer Science from Rutgers University. I still do a bit of programming using everything from C and C++ to Rust and Ada/SPARK. I do a bit of PHP programming for Drupal websites. I have posted a few Drupal modules.
I still get a hand on software and electronic hardware. Some of this can be found on our Kit Close-Up video series. You can also see me on many of our TechXchange Talk videos. I am interested in a range of projects from robotics to artificial intelligence.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: